CULane Dataset을 활용한 UFLD Dataset 구성하기
이 페이지에서는 UFLD (Ultra Fast Lane Detection)와 함께 CULane Dataset을 어떻게 활용하는지 살펴보겠다. 처음엔 어렵게 느껴질 수 있어도 어려운게 아니라 익숙하지 않아서 그러니, 여러번 해보고 익숙해지는 것을 목표로 지속적으로 학습해보자!
포스트 마지막에는 간단한 문제를 통해 복습할 수 있도록 해놓았다. 계속 보면서 익숙해져보자!
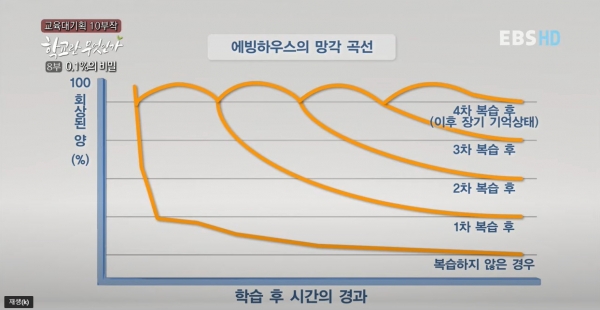 문제 풀이를 통해 잊지 않고 꾸준히 복습하도록 하자.
문제 풀이를 통해 잊지 않고 꾸준히 복습하도록 하자.
UFLD & CULane Dataset 소개
UFLD는 lane detection 네트워크 중 하나로, 기존의 segmentation 방식이 아닌 anchor-based 방식으로 결과를 도출하도록 설계되었다. 본 포스트에서는 특히 CULane Dataset을 활용하여 UFLD의 학습 데이터를 준비하는 방법을 다룬다. 특히 segmentation 데이터셋을 anchor 기반 lane detection에 어떻게 활용할 수 있는지 알아본다.
CULane Dataset Investigation
먼저, CULane Dataset에 대해 간략히 살펴보자.
데이터 출처:
본 데이터셋은 Beijing에서 다양한 운전자들이 운전하는 6대의 차량을 촬영한 데이터로 구성되어 있다. 자세한 설명은 공식 문서를 참고할 수 있다.폴더 구조:
데이터를 압축 해제하면 5개의 driving dataset이 확인되며, 이 중 3개는 Training & Validation set, 나머지 3개는 Test set으로 구성되어 있다.
예를 들어,- Training & Validation set:
driver_23_30frame.tar.gzdriver_161_90frame.tar.gzdriver_182_30frame.tar.gz
- Test set:
driver_37_30frame.tar.gzdriver_100_30frame.tar.gzdriver_193_90frame.tar.gz
- Training & Validation set:
 위 이미지는 CULane Dataset의 폴더 구조를 보여준다.
위 이미지는 CULane Dataset의 폴더 구조를 보여준다.
Annotation 방식:
CULane은 cubic spline을 이용하여 lane marking을 annotation한다.
중요한 점은 segmentation 방식이 아닌 spline을 활용해 annotation을 진행한다는 것이다. segmentation 이미지도 있지만 이것은 spline을 활용해 가공해서 만든 GT인 것이다. 만약 lane marking이 차량에 의해 가려지거나 명확하지 않더라도, 주변 context를 참고하여 annotation을 수행한다. 따라서 이를 활용한 모델도 lane prediction을 통해 예측이 가능하게 된다. 사실 segmentation based lane detection은 이렇게 가려진 부분에 대해서 예측하는 것이 어렵지만 UFLD는 lane shape에 대한 loss function이 있기 때문에 occlusion등의 가려진 부분도 예측이 가능해지는 것이다.파일 구성:
각 폴더 내에는 영상의 프레임을 나타내는 jpg 파일과 해당 annotation 정보가 담긴 txt 파일이 존재한다.
이미지의 크기는 1640 x 590으로, 옆으로 넓은 형태이다.
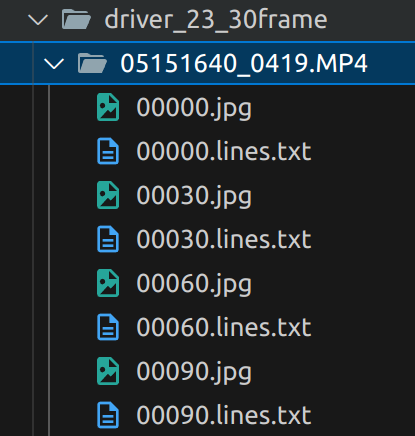 각 이미지와 txt 파일이 어떻게 대응되는지 확인할 수 있다.
각 이미지와 txt 파일이 어떻게 대응되는지 확인할 수 있다.
Annotation Details:
txt 파일에는 최대 4개의 lane marking에 대해, 각 lane마다 여러 개의 line sampling point (x, y 좌표)가 기록되어 있다.
예를 들어, 아래와 같이 값들이 나열된다.1
240.573 590 257.848 580 275.127 570 292.409 560 ... 778.228 290
이 값들은 이미지 상에서 아래에서 위로, 즉 y 값이 10픽셀씩 감소하는 방식으로 sampling되며, 일부 negative나 out-of-bound 값은 lane을 extend하는 과정에서 발생한다.
다만 UFLD에서는 이 feature points를 직접 학습에 사용하지 않고, segmentation ground truth를 가공하여 anchor ground truth를 생성한 후 학습에 활용한다.Additional Annotation Info:
각 이미지에 대응되는 _gt.txt 파일을 확인하면, 이미지 경로, segmentation label 경로, 그리고 네 개의 binary flag (l0–l3)를 통해 각 lane marking의 존재 여부를 확인할 수 있다.
예를 들어,1
<image_path> <segmentation_label_path> 1 1 1 1
이와 같이 l0부터 l3까지 각각 1(존재) 또는 0(부재)로 표현된다. 자세한 내용은 관련 문서를 참고한다.
Test Split:
test_split 폴더 내에는 9개의 카테고리로 구분된 test 데이터셋 리스트가 존재한다.
이는 나중에 모델 성능 평가 시, 다양한 상황에서 얼마나 정확하게 detection하는지 확인하기 위한 중요한 metric으로 사용된다.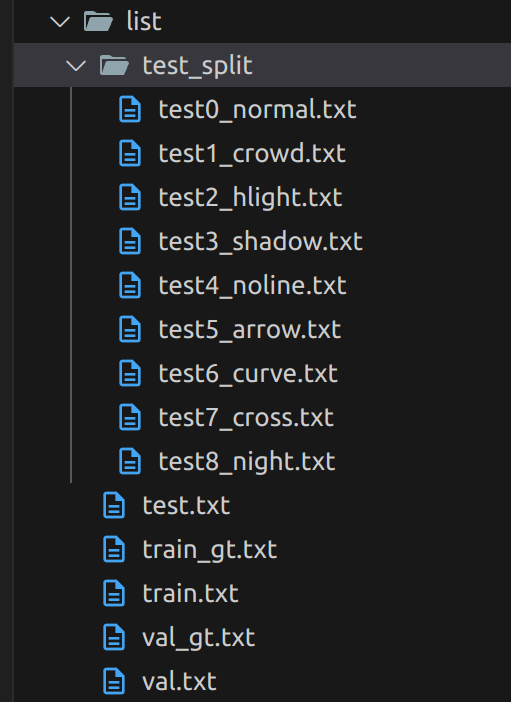
Test split에 포함된 9개의 카테고리 예시Visualization:
이미지와 point-wise annotation을 중첩하여 확인하면 아래와 같은 결과를 얻을 수 있다.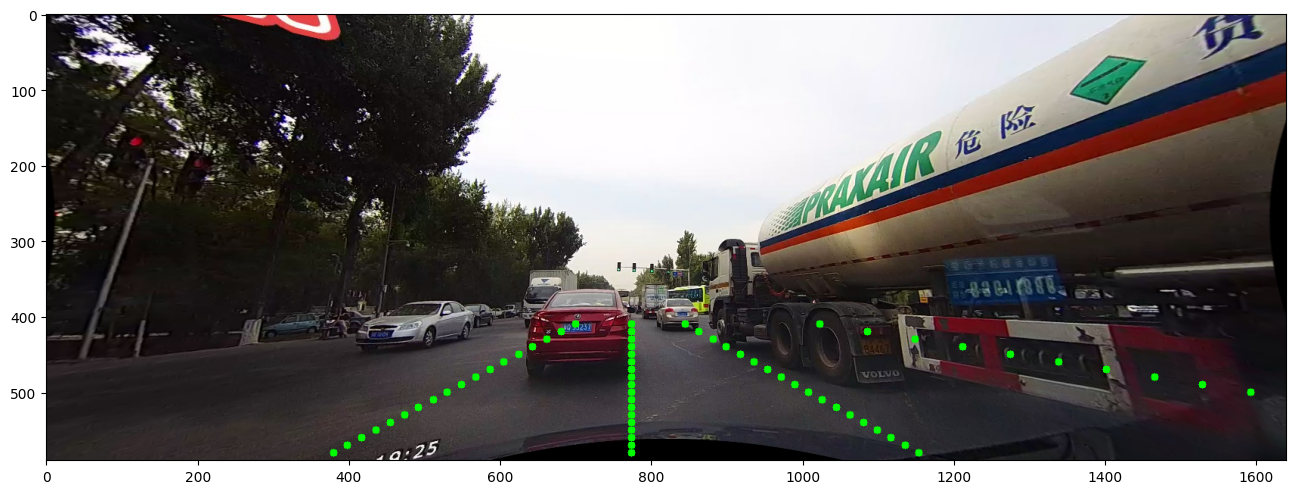
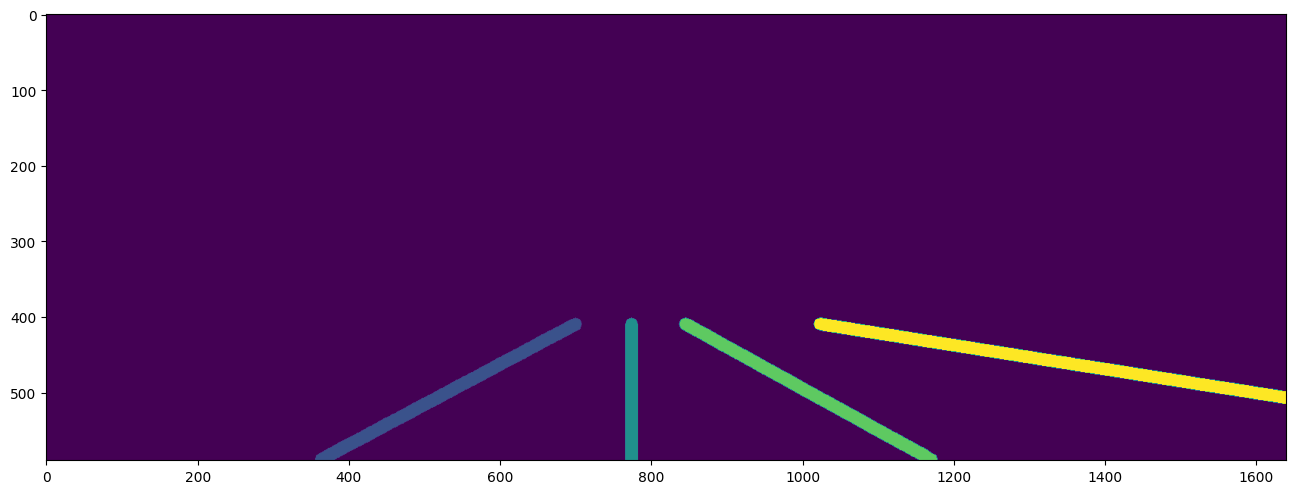
visualization code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# %%
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
# %%
DIR = "./culane/driver_161_90frame/06030819_0755.MP4/"
img = plt.imread(DIR+"00000.jpg")
plt.figure(figsize=(16,18))
plt.imshow(img)
# %%
!cat "./culane/driver_161_90frame/06030819_0755.MP4/00000.lines.txt"
# %%
exist_list = []
listfile = DIR + "00000.lines.txt"
with open(listfile) as f:
for line in f:
line = line.strip()
l = line.split(" ")
exist_list.append([int(eval(x)) for x in l[2:]])
# %%
exist_list[0][0],exist_list[0][1]
# %%
img = img.copy() # 이미지 배열을 writable하게 복사
for j in range(len(exist_list)):
for i in range(0, len(exist_list[j]), 2):
cv2.circle(img, (exist_list[j][i], exist_list[j][i+1]), radius=0, color=(0, 255, 0), thickness=10)
# %%
plt.figure(figsize=(16,18))
plt.imshow(img)
# %%
mask = plt.imread("./culane/laneseg_label_w16/driver_161_90frame/06030819_0755.MP4/00000.png")
plt.figure(figsize=(16,18))
plt.imshow(mask*255);
# %%
np.unique(mask), np.unique(mask*255)
# %%
자 이제 dataset을 다운받아놓고 이제 네트워크 만들기 코딩을 하려하니 벌써 멍하니 모니터를 3시간 동안 바라 보고 있다. 그 뒤에라도 시작하면 다행이다. 보통은 저녁시간이 되어 나가 놀고 이 프로젝트는 포기하게 되는 것이다.

이런 안타까운 상황은 우리네 개발인생에 계속해서 생긴다.
데이터셋을 다운받거나 제작한 다음에 우리는 무엇을 손대야할까?
그 첫 스텝은 데이터 꺼내기 놀이를 해야하는 것이다.
막막할 수 있다. 괜찮다. 거의 정해진 수순을 밟으면 된다. 그닥 창의적인 작업도 아니고 복잡한 작업도 아니다. 한번 세팅해놓으면 별로 건들일 일도 없다. 그래 data folder를 생성하여 dataset.py를 작성해보자.
UFLD dataset 설계하기
이렇게 생각해보십시다.
Dataset과 Dataloader library가 없다고 생각해봅시다.
자 데이터셋이 있다. 그러면 데이터를 이 프로그램 내로 가져와야한다.
가져와서 학습데이터로 넣어주어야한다. 그것도 batch로 넣어주어야 한다.
이를 어떻게 구현할 수 있을지 생각해보자. 우선 requirement를 작성해보는 것이다.
Open Dataset은 이미지와 그에 대응하는 GT가 여러가지 형태로 만들어져있을 것이다.
우리가 활용할 CULane dataset은 리스트 형태로 그 이미지와 GT의 정보가 매칭되어있다.
culane/list/train_gt.txt는 이렇게 되어있다.
1
/driver_23_30frame/05151649_0422.MP4/00000.jpg /laneseg_label_w16/driver_23_30frame/05151649_0422.MP4/00000.png 1 1 1 1
<img_dir> <seg_dir> l0 l1 l2 l3 existance
이렇게 되어있다.
자 그러면 train_gt.txt와 val_gt.txt를 읽어와야한다.
한줄씩 읽어야 한다.
그리고 그것을 파싱해서 이미지와 annotation 파일을 읽어들여야 한다.
아마도 이미지는 텐서로 만들어주거나 resize하는 등 transform해야한다.
이때에 train할때랑 val, test할때의 transform은 달라야 할 것이다.
annotation도 마찬가지로 학습에 용이하게 preprocessing을 진행하여야 한다.
그렇게 이제 요청이 올때마다 input data와 annotation을 꺼내주어야 한다.
그런데 하나씩이 아니고 batch로 꺼내줄 수 있어야 한다.
이런 역할을 하는 class를 만들어야 하는 것이다.
나는 개발자로서 벌써 약 7년째, 석사까지 하면 거의 10년째 개발밥 먹고 살고 있다. 후후 이정도 requirement는 식은죽 먹기로 금방 두드릴 수 있다.
2 hours later…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import os
import torch.Dataset as Dataset
import text
import torchvision.Transform as Transform
import PIL
from Transform import ToTensor, Rotate, Resize
class CULaneDataset: public Dataset:
__init__(self, list_dir, is_train=true):
self.list_dir = list_dir
self.is_train = is_train
self.height = 500
self.width = 500
self.train_transform = Transform(ToTensor(), Resize(height, width), Rotate(20))
self.val_transform = Transform(ToTensor(), Resize(height, width))
parsingDB()
parsingDB(self):
if is_train:
list_txt_dir = os.path.join(self.list_dir, "train_gt.txt")
list_txt = text.import(list_txt_dir)
for i in range(list_txt.size()):
img_path = list_txt[i][0]
l0_ex = list_txt[i][2]
l1_ex = list_txt[i][3]
l2_ex = list_txt[i][4]
l3_ex = list_txt[i][5]
anno_path = list_txt[i][0] - '.jpg' + '.lines.txt'
img = PIL.Image(img_path)
input_data = img.train_transform
# how do I cope with annotation..?
 내 10년!
내 10년!
다시 차근차근 custom dataset에 대한 내용을 보자
Custom Dataset
torchvision.datasets 에서 제공하는 dataset들은 모두 pytorch의 Dataset class를 상속받아 구현 되어 있다. 따라서 직접 custom dataset을 구성 할 때에도 이러한 Dataset 인터페이스를 따를 수 있다.
Dataset class 이해하기
Dataset class를 상속받아 custom dataset을 정의 할 때에는 몇가지 필수 메서드를 구현해야 한다.
__init__(): dataset 객체의 초기화 method. dataset의 경로나 transform 방식등을 설정함__len__(): dataset의 크기를 반환하는 method. 데이터셋의 총 data 개수를 반환해야 한다__getitem__(idx): 특정 index에 해당하는 데이터를 반환하는 method.idx에 해당하는 data를 불러와 이미지와 레이블을 반환하도록 한다.
이를 바탕으로 ufld code의 dataset.py를 분석해보자.
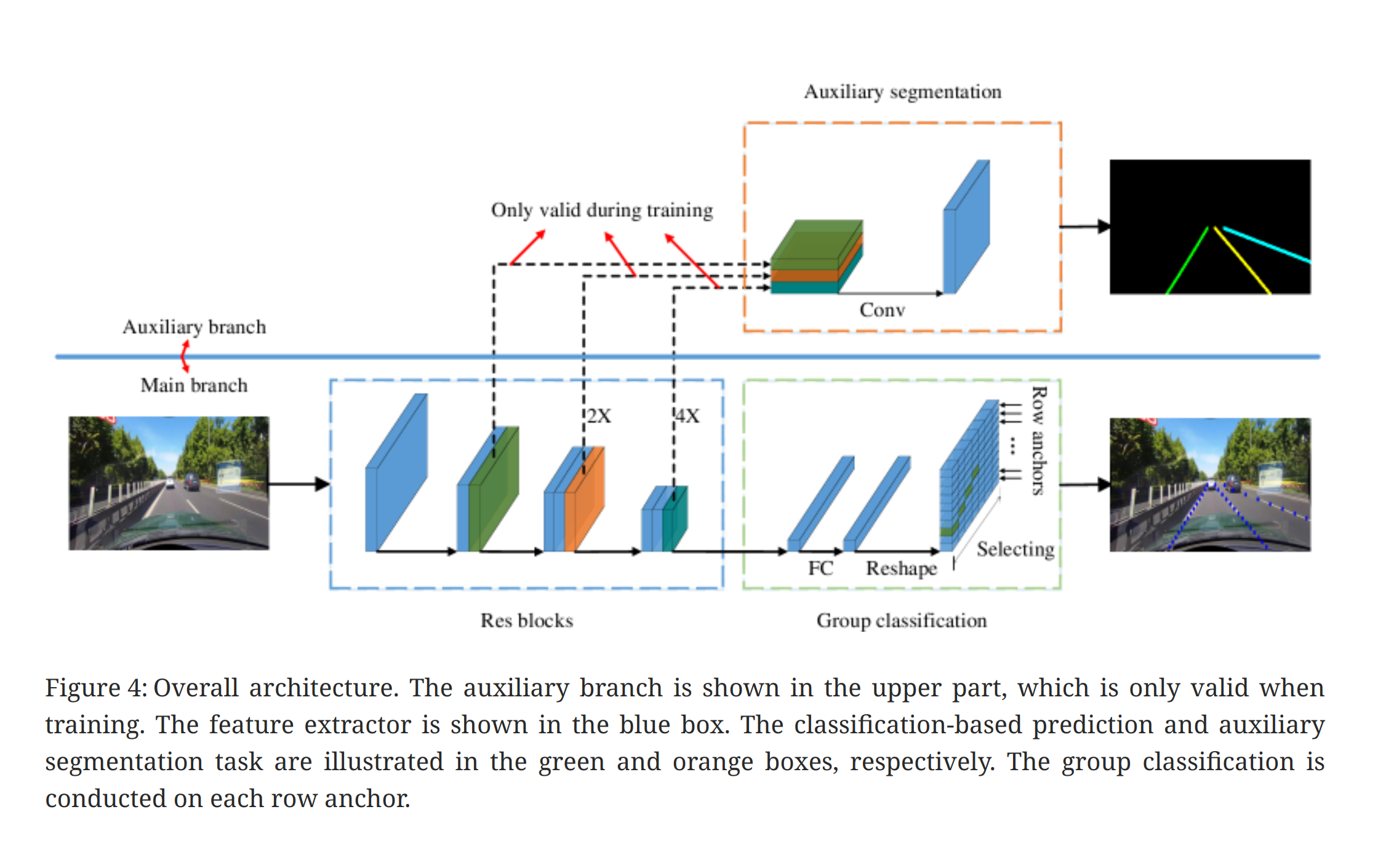 ufld의 architecture는 위와 같다. res blocks가 backbone이 되고 auxiliary branch와 main branch로 나누어져있으며 auxiliary branch는 training시에만 활성화되고, segmentation label을 통해 학습이 진행된다.
ufld의 architecture는 위와 같다. res blocks가 backbone이 되고 auxiliary branch와 main branch로 나누어져있으며 auxiliary branch는 training시에만 활성화되고, segmentation label을 통해 학습이 진행된다.
LaneClsDataset에서 cls랑 seg label을 구하는게 중점이 된다고 보면 된다.
사실상 __getitem__ 을 중점으로 보면 된다.
img와 label 이 있는데 여기서 label path는 seg label img라고 보면 된다.
그리고 모두에 simu_transform을 우선 적용한다. 이거는 image와 seg에 다 적용한다 라는 거라고 보면 된다.
사실상 point wise gt는 활용하지 않는 것으로 보인다.
segmap에서 해당 lane에 해당하는 그거가 있으면 row의 평균값을 내어서 그거를 point wise gt라고 해야하나 row wise gt로 활용하게 된다.
__get_index에서는 extension도해서 어쨌든 그 points들을 뽑아낸다. 그리고 cls_label은 __grid_pts함수를 통해서 그게 그러니까 column으로도 sampling해서 그 개수는 griding_num인데 이걸 통해서 cls label을 뽑아낸다.
그래서 img, cls_label을 아웃풋으로 내게 된다.
전체 코드는 (https://github.com/cfzd/Ultra-Fast-Lane-Detection/blob/master/data/dataset.py) 여기에 있고, 코드 하나하나 좀 뜯어보겠다.
역시나 익숙하지 않을 것이다. 그래도 별수있는가 딥러닝 개발자가되려면 피할 수 없다. 들이대야한다.
def loader_func(*path*): 같은 common 함수는 넘어가도록 하겠다. 여기서는 LaneClsDataset 클래스에 대해서만 확실히 이해하고 넘어가도록 하겠다.
pytorch에서 모든 custom dataset은 torch.utils.data의 Dataset의 파생클래스로 만들어진다.
위에서도 언급했듯이 __init__, __len__, __getitem__은 반드시 구현해야하는 메소드이다.
__init__의 구현에 대해서는 말고, argument에 대해서 알고 넘어가자
1
2
3
4
5
6
7
8
9
10
11
12
13
def __init__(self, root_path, list_path, img_transform=None, target_transform=None, simu_transform=None,\
row_anchor=None, griding_num=50, use_aux=False, segment_transform=None, num_lanes=4):
super(LaneClsDataset, self).__init__()
self.root_path = root_path
self.list_path = list_path
self.img_transform = img_transform
self.target_transform = target_transform
self.simu_transform = simu_transform
self.segment_transform = segment_transform
self.row_anchor = row_anchor # ascending order
self.griding_num = griding_num
self.use_aux = use_aux
self.num_lanes = num_lanes
transform들을 보자.
ufld에서 사용된 transform관련 post에서 설명하겠지만
여기서도 간략하게 설명하자면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
img_transform = transforms.Compose([
transforms.Resize((288, 800)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
target_transform = transforms.Compose([
mytransforms.FreeScaleMask((288, 800)),
mytransforms.MaskToTensor()
])
simu_transform = mytransforms.Compose2([
mytransforms.RandomRotate(6),
mytransforms.RandomUDoffsetLABEL(100),
mytransforms.RandomLROffsetLABEL(200)
])
segment_transform = transforms.Compose([
mytransforms.FreeScaleMask((100, 200)),
mytransforms.MaskToTensor()
])
우선은 target_transform은 ufld 코드에서 사용되지 않는다. 왜 만들어졌는지는 모르겠으나 segment_transform과 매우 유사하다. 다른것은 FreeScaleMask부분인데 이는 다음과 같이 mask 이미지를 resize하는 클래스이다.
1
2
3
4
5
6
7
8
9
# FreeScaleMask: 마스크 이미지를 지정된 size로 resize하는 클래스
class FreeScaleMask(object):
# __init__: target size를 설정합니다.
def __init__(self, size):
self.size = size
# __call__: 마스크 이미지를 target size로 resize 합니다. (Nearest interpolation 사용)
def __call__(self, mask):
return mask.resize((self.size[1], self.size[0]), Image.NEAREST)
segment_transform은 h 100, w 200으로 매우 저화질인데 target_transform은 고화질로서 아마도 segmentation resolution을 바꿔가며 학습에 활용했던 것으로 보인다.
또 simu_transform은 simultaneous transform으로서 이미지와 label에 동일하게 사용되어지는 transform이다. random rotate와 random 상하, 좌우 shift가 있다.
다음으로
1
self.row_anchor = [121, 131, 141, 150, 160, 170, 180, 189, 199, 209, 219, 228, 238, 248, 258, 267, 277, 287]
이거는 predefined된 row_anchor의 위치정보이다.
기준은 height가 288일때를 기준으로 하는 row anchor이기 때문에 h가 288이 아니라면 나중에 보정하게 된다.
griding_num은 grid의 column개수이다. ufld에서는 200개를 쓴다.
use_aux는 auxiliary를 사용하는가에 대한 것이다. 보통은 사용하여 segmentation정보도 학습에 활용하게 된다.
num_lanes는 ufld에서는 4개가 된다.
다음으로는 대망의 __getitem__되시겠다.
이 메소드는 항상 idx를 argument로 가져오게 된다.
1
2
3
4
5
6
7
8
9
10
11
def __getitem__(self, idx):
l_info = self.list[idx].split()
img_path, label_path = l_info[0], l_info[1]
if os.path.isabs(img_path):
img_path = img_path[1:]
if os.path.isabs(label_path):
label_path = label_path[1:]
img_name = img_path
img_path = os.path.join(self.root_path, img_path) # 'culane/driver_23_30frame/05160832_0468.MP4/03015.jpg'
label_path = os.path.join(self.root_path, label_path) # 'culane/laneseg_label_w16/driver_23_30frame/05160832_0468.MP4/03015.png'
이에 따라 이 것의 이미지와 label에 대해 return하도록 구성하여야한다.
l_info는 이렇게 구성되게 된다.
['/driver_23_30frame/05160832_0468.MP4/03015.jpg', '/laneseg_label_w16/driver_23_30frame/05160832_0468.MP4/03015.png', '0', '1', '1', '1']
img path, label path, 네 lane의 existance 정보가 있다.
isabs는 absolute directory인지 를 판단하는건데 둘다 앞에 slash가 있어서 이거 os.path.join하기전에 지워야하므로 1index string부터로 하도록 바꾸는거고
그래서 img_path와 label_path에 각각 path가 mapping되게된다.
1
2
3
4
5
6
img = loader_func(img_path)
label = loader_func(label_path)
if self.simu_transform is not None:
img, label = self.simu_transform(img, label)
이거는 PIL Image로 converting하는거고 image와 label모두 simu_transform을 적용한다.
torchvision에서는 transform단계에서 tensor로 변환전에 PIL(pillow) Image를 사용한다.
simu_transform에서는 ToTensor로 변환하는게 포함되지 않으므로 img, label은 PIL Image 형식을 유지한다.
그 뒤가
1
lane_pts = self._get_index(label)
_get_index 이다. segment label을 input으로 받게 된다.
private method혹은 internal method라고 부르는데 이 class안의 method에서만 호출한다는 뜻이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def _get_index(self, label):
w, h = label.size # 1640, 590
# if the height is not 288, scale the row_anchor accordingly
# row_anchor = [121, 131, 141, 150, 160, 170, 180, 189, 199, 209, 219, 228, 238, 248, 258, 267, 277, 287]
if h != 288:
row_anchor = [int(x * h / 288) for x in self.row_anchor]
else:
row_anchor = self.row_anchor
# create an array to hold lane coordinates
all_idx = np.zeros((self.num_lanes, len(row_anchor), 2))
# all_idx.shape
# (4, 18, 2)
이 함수에서 첫부분은 seg의 size를 확인하는 부분인데 1640, 590으로 이는 row_anchor의 기준 h인 288과 다르게 되므로 compensation? interpolation?을해야한다.
그래서 최종적으로 row_anchor는 다음과 같이 된다.
1
[247, 268, 288, 307, 327, 348, 368, 387, 407, 428, 448, 467, 487, 508, 528, 546, 567, 587]
이미지를 봤을때 위에서 아래쪽으로 정렬되어있다.
그래서 이후에는 이 row_anchor들을 돌면서 line별로 segment가 존재하는지, 존재한다면 어디에 위치해있는지 그리고 그것을 하나의 point로 환산해서 저장하여 반환하는 알고리즘이 돌아가게 된다.
그래서 all_idx에서는 (4, 18, 2)의 shape을 갖게되고 두번째 dim에는 anchor의 순서 index 0 to 17가 저장되고 마지막 dim에서는 row 값, x(lateral) 값이 저장되게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# iterate over each row anchor
for i, row in enumerate(row_anchor):
# Convert the label to a NumPy array and extract the row at position r.
label_r = np.asarray(label)[int(round(row))]
# For each potential lane (lane indices 1 to num_lanes)
for lane_idx in range(1, self.num_lanes + 1):
# Find column indices in this row that match the lane ID.
pos = np.where(label_r == lane_idx)[0]
if len(pos) == 0:
# If no pixels match, record the row number and assign -1 as the column value.
all_idx[lane_idx - 1, i, 0] = row
all_idx[lane_idx - 1, i, 1] = -1
continue
# Otherwise, compute the average column coordinate.
pos = np.mean(pos)
all_idx[lane_idx - 1, i, 0] = row
all_idx[lane_idx - 1, i, 1] = pos
label은 segmentation label이다. 이를 asarray로 np array로 바꿨고 거기에 row번째는 해당하는 width에 값이 저장되어있을 것이다.
그 label에는 1,2,3,4 이렇게 line index가 mapping되어있다.(0,1,2,3 아님 주의)
line index에 해당하는 값이 없다면 pos는 length가 0으로 나올 것이고, 있다면
1
2
3
4
pos
array([673, 674, 675, 676, 677, 678, 679, 680, 681, 682, 683, 684, 685,
686, 687, 688, 689, 690, 691, 692, 693, 694, 695, 696, 697, 698,
699, 700, 701, 702, 703])
이런식으로 y points가 array로 pos에 저장되어있다.
그래서 pos가 없다면 all_idx의 마지막 element에 -1가 되고 있다면 pos를 평균친 point가 저장되게 된다.
만약에 left right에 따라서 안쪽 element로 하고싶다면 그렇게 저장되게 해도 된다. 하지만 UFLD에서는 중간값으로 point를 뽑아내게 된다.
그래서 예를들어 all_idx[1]에는 다음과 같은 값이 저장되게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
all_idx[1]
array([[247. , 688. ],
[268. , 658. ],
[288. , 628.5],
[307. , 602. ],
[327. , 572.5],
[348. , 543. ],
[368. , 514. ],
[387. , 487. ],
[407. , 457.5],
[428. , 428. ],
[448. , 398.5],
[467. , 371. ],
[487. , 344.5],
[508. , -1. ],
[528. , -1. ],
[546. , -1. ],
[567. , -1. ],
[587. , -1. ]])
여기서 이제 끝낼수도 있지만 transform을 통해서 rotation하거나 하면 bottom쪽에는 label이 없어지게 되고, 이를 보완해주기 위해서 아래쪽에 polynomial fitting해서 linear extrapolation하게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
all_idx_cp = all_idx.copy()
for i in range(self.num_lanes):
if np.all(all_idx[i, :, 1] == -1):
continue
valid = all_idx_cp[i, :, 1] != -1
valid_idx = all_idx_cp[i, valid, :]
if valid_idx[-1, 0] == all_idx_cp[0, -1, 0]:
continue
if len(valid_idx) < 6:
continue
valid_idx_half = valid_idx[len(valid_idx)//2:, :] # take the bottom half of the valid indices
p = np.polyfit(valid_idx_half[:, 0], valid_idx_half[:, 1], deg=1)
start_line = valid_idx_half[-1, 0] # the bottom line of the valid row == valid_idx[-1, 0]
pos = find_start_pos(all_idx_cp[i, :, 0], start_line) + 1 # right after valid most bottom idx
fitted = np.polyval(p, all_idx_cp[i, pos:, 0])
fitted = np.array([-1 if y < 0 or y > w - 1 else y for y in fitted])
assert np.all(all_idx_cp[i, pos:, 1] == -1)
all_idx_cp[i, pos:, 1] = fitted
# if any row coordinate is unexpectedly -1, trigger debugging.
if -1 in all_idx[:,:,0]:
pdb.set_trace()
return all_idx_cp
이부분은 핵심적인 부분은 아니니 pass하겠다.
이제 extrapolation까지 된 lane gt points들이 얻어지게 된다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
lane_pts[1]
array([[247. , 688. ],
[268. , 658. ],
[288. , 628.5 ],
[307. , 602. ],
[327. , 572.5 ],
[348. , 543. ],
[368. , 514. ],
[387. , 487. ],
[407. , 457.5 ],
[428. , 428. ],
[448. , 398.5 ],
[467. , 371. ],
[487. , 344.5 ],
[508. , 313.1984021 ],
[528. , 284.54197708],
[546. , 258.75119457],
[567. , 228.66194831],
[587. , 200.0055233 ]])
이 결과는 row에 따른 pixel의 output이 되고 이제 이 y값을 griding_num에 따라 일정하게 grid로 잘라서 해당 grid에 label이 있는지 없는지 classification하는 method가 _grid_pts 가 된다
1
2
3
4
5
6
7
8
9
10
11
12
13
def _grid_pts(self, pts, num_cols, w):
num_lane, n, n2 = pts.shape
col_sample = np.linspace(0, w - 1, num_cols) # making column grids
assert n2 == 2
to_pts = np.zeros((n, num_lane)) # n is the number of row samples
for i in range(num_lane):
pti = pts[i, :, 1] # ith lane x points
interval = col_sample[1] - col_sample[0]
to_pts[:,i] = np.asarray([int(pt // interval) if pt != -1 else num_cols for pt in pti])
return to_pts.astype(int)
input으로 lane points, # of columns(grid 개수), image width가 된다.
결론적으로는 이 결과는
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
cls_label
array([[200, 83, 97, 109],
[200, 79, 101, 119],
[200, 76, 105, 129],
[200, 73, 108, 138],
[200, 69, 112, 148],
[200, 65, 116, 158],
[200, 62, 120, 168],
[200, 59, 123, 177],
[200, 55, 127, 185],
[200, 51, 131, 195],
[200, 48, 134, 200],
[200, 45, 138, 200],
[200, 41, 142, 200],
[200, 38, 146, 200],
[200, 34, 149, 200],
[200, 31, 153, 200],
[200, 27, 157, 200],
[200, 24, 160, 200]])
이와 같은 class label을 반환한다
각 열마다 해당 lane으로 classification된게 있다면 그것의 grid index값이 저장되어있고 만약에 없다면 200이 저장되어있다.
row anchor 개수가 18개이므로 row 개수는 18개이다.
그래서 그 이후에 만약 use_aux가 True이면 seg_label까지 반환해주고 하여
1
2
3
4
5
6
7
8
9
10
11
12
13
14
if self.use_aux:
assert self.segment_transform is not None
seg_label = self.segment_transform(label)
if self.img_transform is not None:
img = self.img_transform(img)
# return a tuple according to the provided flags.
if self.use_aux:
return img, cls_label, seg_label
if self.load_name:
return img, cls_label, img_name
return img, cls_label
최종적으로 img, cls_label, seg_label 이렇게 이미지, class label, segmentation label을 반환하게 된다.
이렇게하면
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# LaneClsDataset 인스턴스 생성 (auxiliary segmentation 사용)
dataset = LaneClsDataset(root_path=data_root,
list_path=list_path,
img_transform=img_transform,
target_transform=target_transform,
simu_transform=simu_transform,
row_anchor=culane_row_anchor,
griding_num=griding_num,
use_aux=True,
segment_transform=segment_transform,
num_lanes=4)
# 데이터셋에서 임의의 샘플 인덱스 선택 (예: 1000번째)
try:
img, cls_label, seg_label = dataset[1000]
except IndexError:
print("샘플 인덱스 1000이 존재하지 않습니다. 데이터셋 크기를 확인하세요.")
exit(1)
이렇게 data를 불러올 수 있게 되는 것이며 이것이 pytorch Dataset의 역할이 된다.
이렇게 반환된 이미지와 cls_label과 seg_label을 visualize해보면
 augmentation과 그에따라 label이 잘 ovelay되는 것을 확인 할 수 있다.
augmentation과 그에따라 label이 잘 ovelay되는 것을 확인 할 수 있다.
visualization code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
def visualize_lane_labels(img, cls_label, seg_label, row_anchor, griding_num=200, w=800, alpha=0.5):
"""
원본 이미지 위에 cls_label과 seg_label을 함께 시각화합니다.
Args:
img: 원본 이미지 (PIL Image 또는 tensor)
cls_label: (n, num_lanes) 크기의 classification label 행렬
seg_label: segmentation mask (tensor 또는 numpy array)
row_anchor: row 위치 리스트
griding_num: grid 열 개수
w: 이미지 너비
alpha: segmentation overlay 투명도
Returns:
lane 마킹과 segmentation overlay가 포함된 시각화 이미지
"""
import matplotlib.pyplot as plt
import numpy as np
import cv2
from PIL import Image
import torch
# tensor인 경우 numpy로 변환 (정규화 해제 포함)
if isinstance(img, torch.Tensor):
if img.shape[0] == 3 and img.max() <= 1:
mean = torch.tensor().view(3, 1, 1)
std = torch.tensor().view(3, 1, 1)
img = img * std + mean
img = img.permute(1, 2, 0).cpu().numpy()
img = np.clip(img, 0, 1)
elif isinstance(img, Image.Image):
img = np.array(img) / 255.0
vis_img = img.copy()
h, w_img = vis_img.shape[:2]
if isinstance(seg_label, torch.Tensor):
seg_label = seg_label.cpu().numpy()
seg_overlay = np.zeros_like(vis_img)
seg_colors = [
(0, 0, 0.7), # Dark blue
(0, 0.7, 0), # Dark green
(0.7, 0, 0), # Dark red
(0.7, 0.7, 0), # Dark yellow
(0.7, 0, 0.7), # Dark magenta
(0, 0.7, 0.7), # Dark cyan
]
# segmentation mask의 사이즈가 다르면 resize
if len(seg_label.shape) == 2:
seg_h, seg_w = seg_label.shape
if seg_h != h or seg_w != w_img:
seg_label = cv2.resize(seg_label.astype(np.float32), (w_img, h),
interpolation=cv2.INTER_NEAREST).astype(seg_label.dtype)
else:
if len(seg_label.shape) == 3:
c, seg_h, seg_w = seg_label.shape
if seg_h != h or seg_w != w_img:
resized_seg = np.zeros((c, h, w_img), dtype=seg_label.dtype)
for i in range(c):
resized_seg[i] = cv2.resize(seg_label[i].astype(np.float32), (w_img, h),
interpolation=cv2.INTER_NEAREST).astype(seg_label.dtype)
seg_label = resized_seg
# segmentation overlay 채우기
if len(seg_label.shape) == 2:
for lane_class in range(1, int(seg_label.max()) + 1):
mask = seg_label == lane_class
color = seg_colors[(lane_class - 1) % len(seg_colors)]
for c in range(3):
seg_overlay[:, :, c][mask] = color[c]
else:
num_classes = seg_label.shape[0]
for lane_class in range(1, num_classes): # background 제외
mask = seg_label[lane_class] > 0
color = seg_colors[(lane_class - 1) % len(seg_colors)]
for c in range(3):
seg_overlay[:, :, c][mask] = color[c]
vis_img_with_seg = cv2.addWeighted(vis_img, 1, seg_overlay, alpha, 0)
cls_colors = [
(0, 0, 1), # Blue
(0, 1, 0), # Green
(1, 0, 0), # Red
(1, 1, 0), # Yellow
(1, 0, 1), # Magenta
(0, 1, 1), # Cyan
]
col_sample = np.linspace(0, w - 1, griding_num)
col_interval = col_sample[1] - col_sample[0]
num_lanes = cls_label.shape[1]
for lane_idx in range(num_lanes):
color = cls_colors[lane_idx % len(cls_colors)]
lane_points =
for i, row in enumerate(row_anchor):
col_idx = cls_label[i, lane_idx]
if col_idx < griding_num:
col_pos = col_idx * col_interval
if h != 288:
row_pos = int(row * h / 288)
else:
row_pos = row
lane_points.append((int(col_pos), row_pos))
for i in range(len(lane_points) - 1):
cv2.line(vis_img_with_seg, lane_points[i], lane_points[i+1], color, thickness=2)
cv2.circle(vis_img_with_seg, lane_points[i], radius=3, color=color, thickness=-1)
if lane_points:
cv2.circle(vis_img_with_seg, lane_points[-1], radius=3, color=color, thickness=-1)
plt.figure(figsize=(12, 8))
plt.imshow(vis_img_with_seg)
plt.title("Lane Visualization with Segmentation")
plt.axis('off')
plt.show()
return vis_img_with_seg
if __name__ == '__main__':
import torchvision.transforms as transforms
import data.mytransforms as mytransforms
import matplotlib.pyplot as plt
# DATA 경로 및 파라미터 설정 (필요에 따라 수정)
data_root = 'culane'
list_path = os.path.join(data_root, "list/train_gt.txt")
culane_row_anchor = [121, 131, 141, 150, 160, 170, 180, 189, 199, 209, 219, 228, 238, 248, 258, 267, 277, 287]
griding_num = 200
# 이미지 및 타겟 변환 정의
img_transform = transforms.Compose([
transforms.Resize((288, 800)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
target_transform = transforms.Compose([
mytransforms.FreeScaleMask((288, 800)),
mytransforms.MaskToTensor()
])
simu_transform = mytransforms.Compose2([
mytransforms.RandomRotate(6),
mytransforms.RandomUDoffsetLABEL(100),
mytransforms.RandomLROffsetLABEL(200)
])
segment_transform = transforms.Compose([
mytransforms.FreeScaleMask((36, 100)),
mytransforms.MaskToTensor()
])
# LaneClsDataset 인스턴스 생성 (auxiliary segmentation 사용)
dataset = LaneClsDataset(root_path=data_root,
list_path=list_path,
img_transform=img_transform,
target_transform=target_transform,
simu_transform=simu_transform,
row_anchor=culane_row_anchor,
griding_num=griding_num,
use_aux=True,
segment_transform=segment_transform,
num_lanes=4)
# 데이터셋에서 임의의 샘플 인덱스 선택 (예: 1000번째)
try:
img, cls_label, seg_label = dataset[1000]
except IndexError:
print("샘플 인덱스 1000이 존재하지 않습니다. 데이터셋 크기를 확인하세요.")
exit(1)
# 비주얼라이제이션 함수 호출
visualize_lane_labels(img, cls_label, seg_label, culane_row_anchor, griding_num=griding_num)
이렇게 culane dataset을 활용하여 ufld에서 어떻게 Dataset util을 통해 data를 불러오고 가공하고 반환하게 되는지 알게되었다.
글이 길어져서 dataloader는 다음에 작업하도록하고 아래에 문제를 통해서 복습하고 기억할 수 있도록 여러 문제를 적어보았다. (사실 이건 손아파서 GPT시켰다.)
어려운게 아니고 익숙하지 않은 것이다. 자꾸보고 만나고 얘기해서 친해지자. 딥러닝은 그럴 가치가 있는 친구니까.
복습 문제
1. 파이썬에서 클래스를 정의할 때 사용하는 키워드는 무엇인가요?
답: class
2. 파이썬에서 클래스의 생성자를 정의하는 특별한 메서드 이름은 무엇인가요?
답: __init__
3. 다음 코드의 출력 결과는 무엇인가요? 1
2
my_list = [1, 2, 3, 4, 5]
print(my_list[1:3])
1
2
my_list = [1, 2, 3, 4, 5]
print(my_list[1:3])
답: [2, 3]
4. PyTorch에서 custom dataset을 만들기 위해 상속해야 하는 기본 클래스 이름은 무엇인가요?
답: torch.utils.data.Dataset
5. custom dataset 클래스에서 반드시 구현해야 하는 세 가지 주요 메서드는 무엇인가요?
답: __init__, __len__, __getitem__
6. CULane Dataset의 segmentation label에서 각 차선은 어떤 값으로 표현되나요?
답: 1부터 4까지의 정수 값 (1, 2, 3, 4)
7. UFLD의 `LaneClsDataset`에서 이미지 높이가 288이 아닌 경우, `row_anchor` 값들은 어떻게 조정되나요?
답: 이미지 높이와 288의 비율에 따라 각 row_anchor 값에 곱해져 보정됩니다.
8. `LaneClsDataset`의 `_get_index` 메서드는 segmentation label을 입력으로 받아 어떤 형태의 출력을 생성하나요?
답: 각 차선별로 row anchor 위치에서의 (row, x좌표)를 담고 있는 numpy 배열 (shape: (num_lanes, len(row_anchor), 2))
9. `LaneClsDataset`의 `_grid_pts` 메서드는 어떤 역할을 하나요?
답: 추출된 차선 좌표들을 이미지 너비에 따라 griding_num개의 컬럼으로 나누고, 각 row anchor 위치에서 해당 차선이 속하는 grid index를 classification label 형태로 변환합니다.
10. UFLD 학습 시 auxiliary loss를 사용하기 위해 `LaneClsDataset`에서 추가적으로 반환되는 데이터는 무엇인가요?
답: 원본 segmentation label에 segment_transform을 적용한 seg_label
11. `np.where()[0]`에서 `[0]`을 붙이는 이유는 무엇인가요?
💡 정답 np.where는 조건을 만족하는 인덱스를 담은 튜플을 반환합니다. 튜플의 첫 번째 요소가 실제 인덱스 배열이므로, [0]을 사용하여 해당 배열에 접근합니다. 예) (array([10, 11, 12]),) → [0]으로 실제 인덱스 접근
12. `super()` 호출을 Python3 스타일로 고치시오
1
super(LaneClsDataset, self).__init__()
💡 정답
1
super().__init__()
Python3에서는 클래스명과 self를 생략할 수 있습니다.
13. 라인 extrapolation에 `polyfit`을 사용하는 이유는 무엇인가요?
💡 정답 회전 또는 이동 등의 데이터 증강으로 인해 차선의 하단 일부가 이미지 경계 외부로 가려질 수 있습니다. 이때, 남아있는 상단 부분의 포인트를 이용하여 직선의 추세를 예측하고 자연스럽게 차선을 연장하기 위해 polyfit을 사용합니다.
14. `cls_label`에 200이 들어가는 경우는 언제인가요?
💡 정답 해당 row anchor 위치에 차선이 존재하지 않는 경우 (_gt.txt에서 해당 차선의 존재 유무가 0으로 표시된 경우) 또는 _get_index() 함수의 결과로 해당 row의 모든 포인트가 -1로 처리된 경우입니다.
15. 파이썬에서 클래스 상속은 어떻게 구현하나요?
클래스 정의 시 괄호 안에 부모 클래스를 명시하여 상속받습니다. 예를 들어:
1
2
class ChildClass(ParentClass):
pass
16. 파일을 읽을 때 주로 사용하는 Python 내장 함수는 무엇인가요?
open() 함수를 사용하여 파일을 열고, read() 또는 readlines() 메서드로 파일 내용을 읽습니다.
17. PyTorch의 `torch.utils.data.Dataset`을 상속받아 custom dataset을 만드는 이유는 무엇인가요?
DataLoader와 호환되어 배치 단위의 데이터 로딩, 셔플링, 멀티프로세싱 등을 쉽게 처리할 수 있기 때문입니다.
18. `transforms.Compose`의 역할은 무엇인가요?
여러 개의 transform 함수를 순차적으로 적용하여 이미지 전처리 파이프라인을 간결하게 구성할 수 있도록 합니다.
19. UFLD에서 segmentation label 대신 lane anchor(또는 grid 기반의 cls label)를 사용하는 이유는 무엇인가요?
segmentation 방식보다 anchor 기반 방식이 occlusion 문제를 해결하고, 차선의 형태와 위치 정보를 더 효율적으로 학습할 수 있기 때문입니다.
20. `__getitem__` 메서드가 중요한 이유는 무엇인가요?
각 인덱스에 해당하는 데이터를 불러와 전처리하고, DataLoader가 배치로 데이터를 공급할 수 있도록 도와주기 때문입니다.
21. 코드에서 `np.polyfit`과 `np.polyval` 함수는 어떤 역할을 수행하나요?
np.polyfit은 주어진 점들로부터 회귀식을 구하고, np.polyval은 이 회귀식을 이용하여 예측 값을 계산하는 데 사용됩니다.
22. 데이터 augmentation 시 이미지와 label에 동일한 변환을 적용하는 이유는 무엇인가요?
이미지와 레이블의 정합성을 유지하여, 변환 후에도 올바른 대응 관계를 보장하기 위함입니다.
23. UFLD에서 auxiliary branch를 사용하는 목적은 무엇인가요?
auxiliary branch는 보조적인 segmentation task를 수행하여 메인 branch의 학습을 보완하고, 전체 차선 감지 성능을 개선하기 위해 사용됩니다.